

short
- OpenRouter launched Fusion on June 12, a server-side API that sends a prompt to a set of models, then uses a judge and synthesizer to combine the best answer.
- According to Perplexity’s DRACO benchmark, a budget board made up of different AIs reached 1% of Fable 5 at roughly half the cost.
- The technology came to light when US export control regulations forced Anthropic to suspend Fable 5 and Mythos 5.
OpenRouter has launched an API built on a simple bet: that a group of cheap AI models, combined in the right way, can match a single expensive model. And by “expensive” they mean Claude Myth 5.
The product is called Fusion. It sends a prompt to multiple models in parallel, and then uses the judge and composite model to combine the results into a single answer.
The timing is coincidental. Shortly after his release Myth 5 And Mythos 5 Last week, US export control directives forced Anthropic to suspend these forms for every foreign national worldwide, citing a disputed discovery of the prison break. OpenRouter broke the news to
Introducing Fusion API, the smartest composite model on the market.
Fusion delivers fable-level intelligence at half the price.
How it works 👇 pic.twitter.com/OTUQAdTQjU
– OpenRouter (@OpenRouter) June 13, 2026
How to get legend cheap
When you send a prompt to Fusion, OpenRouter fires it over a palette of forms in parallel. Each one gets web search tools and bash tools.
The judge’s model then extracts points of consensus, contradictions, and blind spots from each answer. After this phase is over, the synthesizer — Claude Opus 4.8 by default — writes the final answer based on this analysis.
Everything happens server side. You can switch your form string to “openrouter/fusion” for the default panel, add a fusion widget so your model calls it selectively, or create a custom panel in the Fusion chat room without code.
OpenRouter has tested this on Draco,Perplexity benchmark is built on real user deep search queries. Fable 5 combined with OpenAI’s GPT-5.5 and made by Opus topped the chart with 69%. Solo Fable scored 65.3%, although seven of its 100 missions were never played because its content filters blocked them.
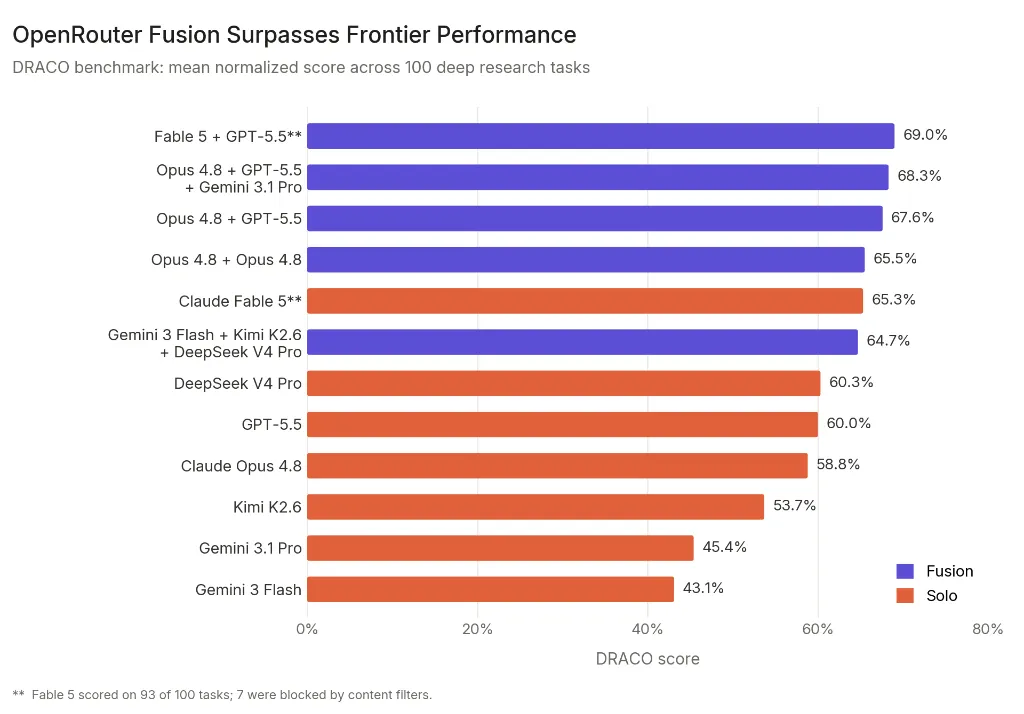
The cheaper combination is the one OpenRouter wants to remember: The cheap Gemini 3 Flash with open source Chinese models Kimi K2.6 and DeepSeek V4 Pro, integrated and tuned by Opus, achieved 64.7% – beating Solo GPT-5.5 (60%) and Solo Opus 4.8 (58.8%) directly and landing within a point of Fable at about half the cost.
Even pairing the Opus 4.8 with a discrete copy by itself scored 65.5%, a jump of 6.7 points over the single Opus; OpenRouter says that roughly three-quarters of this lift comes from the tuning step itself, and the rest from true model diversity.
One drawback: Giving the panel direct access to the web allows models to show DRACO’s own rubric in search results, a contamination risk that OpenRouter describes as coincidental rather than intentional. The fix took one line of configuration to exclude Standard hosting domains from search tools, and each number posted reflects this cleanup.
Worth a try?
OpenRouter confirmed up front that Fusion is not a complete replacement for Fable. DRACO is moving beyond long-term work, as Fable is said to still be leading it, and for programming, Fusion acts as a tool that the programming model calls selectively, not swapped wholesale — a caveat that reflects what Decryption I found the test deepclouda cheaper backend swap that keeps the Claude Code agent loop intact but still falls behind Opus on the most difficult reasoning tasks.
The regular model still deals with everyday things. Fusion is there for questions where one model might miss something important, and having some viewpoints that compare each other really moves the needle.
For deep research, complex planning, or anything where contrasts are important, room seems to help.
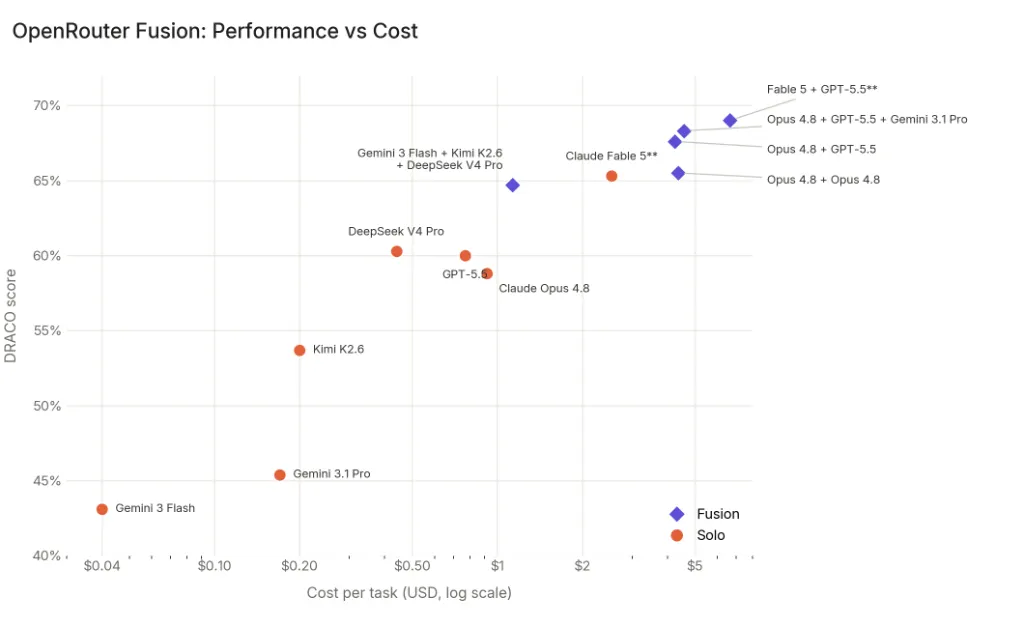
The diagrams illustrate the basic point well enough: in this line of work, an expensive single model is no longer the only way to get a solid composition. A set of models that are still easy to obtain, and put together, can sit right next to them on the results while presenting a much smaller bill.
The launch topic split almost two to one favorably on sentiment tracking. Artificial intelligence researcher Andrew Trask Shoot it “A much bigger deal than it seems,” he said, arguing that frontier labs will never own borders alone again. Skeptics He was pushed back on the framework, citing poor coding results, poor tool recall, and lack of transparency since Fable 5 is no longer available to compare results.
Fusion runs entirely on models that are routed through the OpenRouter infrastructure, so it does not solve the export control problem at source. Anyone banned from Fable 5 now has options: a Fusion board, a backend swap like DeepClaude, or open-weight alternatives like GLM-5.2 It may not be the best but it’s good enough for the price.
Daily debriefing Newsletter
Start each day with the latest news, plus original features, podcasts, videos and more.


