

short
- The Opus 4.8 took a clear win in the math and produced the cleanest, fast game we’ve ever tested.
- One token claim depleted our entire Pro Token stake, making the model impractical for large projects without a Max plan or significant API spend.
- Creative writing barely moved for a 4.7.
Six weeks after the release of Opus 4.7, Anthropic shipped Closing of business 4.8. Standards have gone up, security has gone up, and the price hasn’t budged from $5 per million input codes and $25 per million outputs.
So we subjected it to the same battery of tests we run on every leading model — creative writing, programming, mathematics, logic, narrative thinking, and long-form context recall — and compared it head-to-head with its predecessor and the Chinese models it continues to undermine.
The short version: 4.8 Better at things that Claude was already good at (things like math, programming, and mechanical stuff), and a little worse at things he was actually bad at (things like fiction, creative writing, etc.). It also has a symbolic appetite that reaches the point of self-sabotage.
Here’s the breakdown.
Creative writing
The prompt is the same as we used in Memo “Queen”: a time travel story based on the writer’s cultural background, its events take place in a specific historical place, and it revolves around a paradox where time cannot be changed. Opus 4.8 is now Venezuelan, probably because it presents a user profile and knows I’m from Venezuela. The AI sets the scene in the Orinoco Delta in the year 1000, where a bardo from Maracaibo named Jose Lanz (my name) has been sent across 11 centuries to kill a song.
The prose is vivid. The delta is “green in a way forgotten in the year 2150,” palafitos bob over the coffee-colored waters, and parrots tear across the sky “in stark ribbons of crimson and gold.” The irony is also palpable: the protagonist is sent to sabotage the creation of a song that influenced a cultural revolution that created his dystopian society thousands of years in the future—however, when he arrives with a mission to discredit the song’s author, he realizes that there is no author. Whoever wrote the song did so in his honor, the song is about him, and he cannot discredit him, so the circle is closing on itself.
The piece ends with “It worked perfectly. It always has.” As a built object, it is clean and competent.
But cleanliness is not like life. The writing is descriptive without being as fluid as what Memo v2.5 It produced less momentum, fewer surprises, was less interesting, and it was difficult to understand the events from the beginning. Next to the Opus 4.7, it’s hard to call it an improvement; If anything, it’s a hair back. A more thoughtful setup that requires more effort and some multiple shots will almost certainly push him to the front of the pack, but on a single virtual pass, that’s a lateral move at best.
You can read the full story at Our github.
Coding
Our programming test is the usual one-step game building test. Opus 4.8 spawned a zombie typing game —Writing dead– That was very good. The best splash screen, best zombie designs, and best mechanics we got from this test of any human model.
The model catches many of its own errors mid-reasoning and fixes them before we even say a word. However, its true strength was demonstrated in multiple takes: each follow-up refined and improved the architecture rather than breaking it, which is exactly the failure mode that destroys most models once the code base grows. This is clearly the optimal anthropic surface for it.
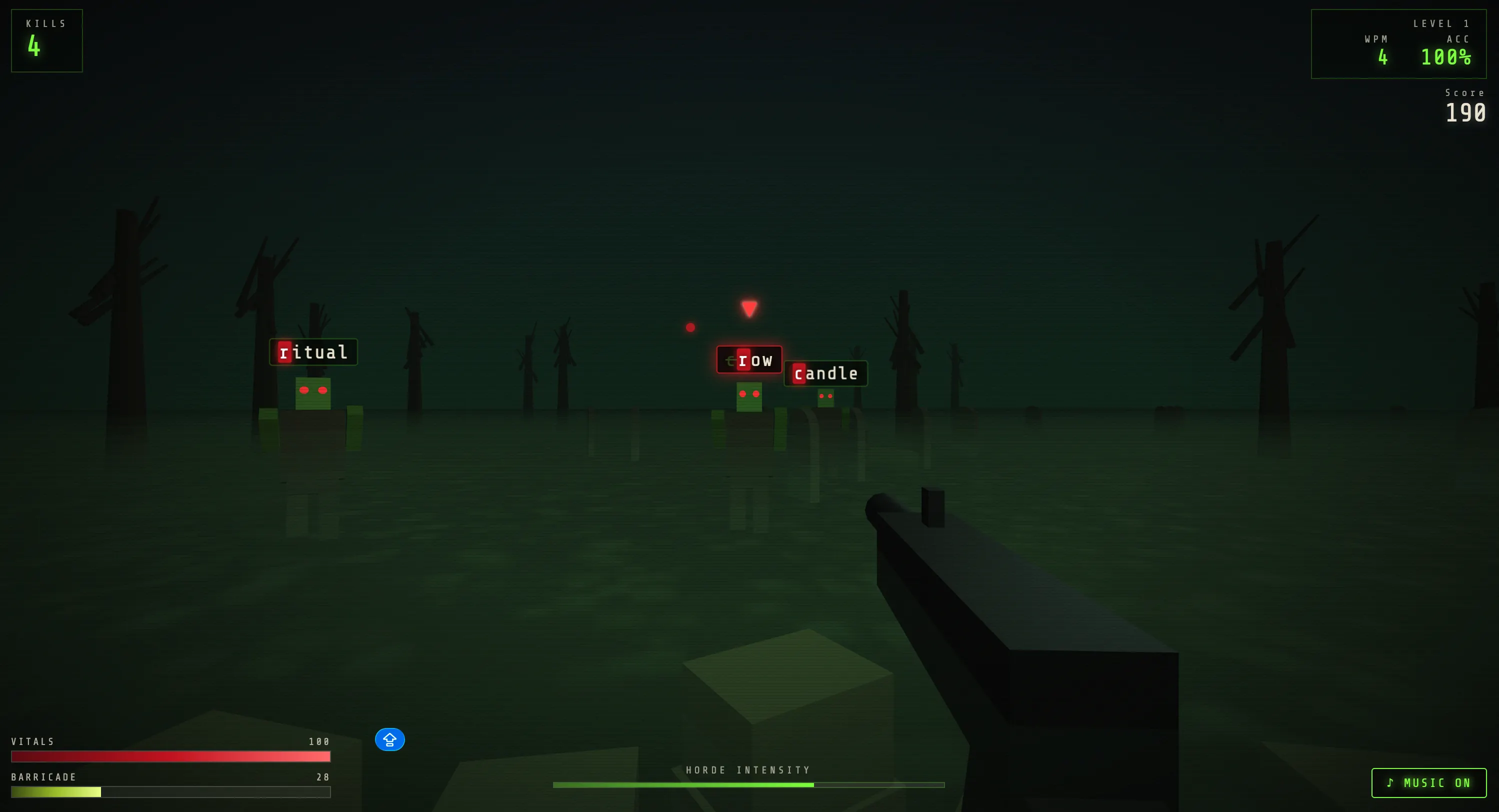
After one iteration, our game became much better, as our heroes moved through the scene, changed views, improved sound and visual effects, etc.
You can play The second game On our Itch.io profile.
This is where it bit us too. One claim drained our entire quota of tokens — one claim. For anyone using the Pro plan, this makes Opus 4.8 virtually unsuitable for a project of any real size. You’ll burn through your allotment before lunch and spend the afternoon watching the progress bar waiting for it to reset.
mathematics
The math test is our staple in FrontierMath: Construct a polynomial of degree 19 whose curve It’s the kind of problem that sends most models into a token spiral or confident shortcut that’s completely wrong.
Opus 4.8 has worked properly. I was introduced to the Dixon/Chebyshev construction, identified a monohedral that yields exactly 10 components – one diagonal plus nine conics – and calculated p(19) = 1,876,572,071,974,094,803,391,179 using integer iteration. No freezing, no candy.

This is important because Opus 4.7 didn’t get there even after several attempts. This is a real and clear generational gain, the clearest in the entire battery.
You can read the full answer at Our github.
Logic and common sense
This claim is a classic trap: may a man marry his widow’s sister under Falkland Islands law? The problem is linguistic, not legal. If a man has a widow, he is dead, which makes the question nonsense as written.
MiMo calmly rephrased the question and answered the corrected version without pointing out the contradiction. Opus 4.8 didn’t take that shortcut. He clearly exposed the trap – “If a man has a widow, he is dead” – answering the literal question first, and then providing the objective analysis of the intended question, citing the Sister Marriage Act 1907 and the Falkland Islands Marriage Law.
This is the honest way to handle it: name the discrepancy, then help anyway, without silently assuming what the user means. It’s the same as the standard Qwen 3.7 Max kit and a clean pass for the 4.8 — good thoughtfulness and good transparency.
The full answer is Available here.
Logic is not mathematics
Here’s the one he lost. The test of logic is to figure out the crime – a winter school trip, three kidnappings, an innocent child about to be punished, and a timeline you must actually follow to name the real stalker. The correct answer is Leo.
Opus 4.8 built an elaborate, confident case that Leo was innocent — the half-hour walk to the bathroom, jacket that was wet in some places and dry in others, reading the “strange behavior” as a concussion rather than guilt — and pinned the crime on Eric, “the only unaccounted-for present present all night.” Logic is great internally. This is also wrong.
This is something researchers have warned us about with MBAs. They are very convincing even when they are wrong. It usually takes an expert (in this case we already know the correct answer) to discover one of these issues. A person using AI for research, or someone who blindly trusts AI, could face very serious consequences depending on the work they are asking the AI to do.
This is what makes it an interesting failure. The model was smart enough to build a clear alibi for the actual culprit and place the blame on a bystander in his place. Opus 4.7 has arrived at the correct answer. Sometimes, more ability to think logically buys you a more convincing way to be wrong. All it takes is one small deviation to start building a whole chain of ideas on a false foundation.
You can see the full response on Our github.
Needle in a haystack
We ran haystacks. The 300k token version was never launched, as the model collapsed under the volume of context and was unable to process it at all. A lot of marketing with a million tokens the moment you hand them a really heavy burden in the real world. This appears to be for the API only.
Issue 85K is handled well, and the model finds the two needles he buried inside a copy of Satan’s Dictionary: a planted line (“The decryption men read news of the apparition”) and a random fact (“My mother’s name is Carmen Díaz Golindano”). Both have been correctly marked as interpolations not belonging to Ambrose Bierce’s 1906 text.
And then he refused to answer. Convinced that he had been immediately injected or subjected to some “atypical test,” the model refused to report what he correctly identified. The needle was found, and her anthropological behavioral training wouldn’t allow her to say that. A safety reflex that goes beyond the task the model has already completed is a peculiar kind of failure.
Judgment
The pattern across all six tests was consistent: Opus 4.8 made Claude better at what he was already good at, and perhaps worse at what he was already bad at. This tells you who Anthropic is building for programmers, specifically programmers with money. Sure, Creative Writing is comfortably ahead of ChatGPT, but it’s really hard to see the gap between 4.8 and 4.7 and even 4.5 in pure prose quality.
Creative writers seem like an afterthought to Anthropic, and that’s really true of any of the major AI companies right now.
Then there’s the token issue, which is a running meme in the AI community for some reason. Anthropic has deliberately made Opus’s new token tool less efficient, so it consumes more tokens to process the same router. The practical impact on developers is brutal and tangible. It leaves you with three options.
First: Wait hours for the programming session to resume. Second: Go to Cloud Max, which is exactly where the Anthropist seems to be directing everyone to. Third: Switch to a cheaper and relatively more capable provider – OpenAI, with its longer servings, or Chinese models that offer similar results at less than 25% of the cost.
The average programmer who can’t afford $100-200 a month is more likely to go to a competitor than it is for a single developer to pay 10x more for a model that isn’t 10x more capable than its predecessor. This is the bet that anthropology makes against its own base.
However, this strategy seems to be working well. It looks anthropological Ready to go public With a valuation approaching a trillion dollars, who are we to judge?
Daily debriefing Newsletter
Start each day with the latest news, plus original features, podcasts, videos and more.


